Gotta Cache 'Em All: Creating a Pokédex with Rust and WebAssembly
published
last modified
27kb
When I think of the word cache, it evokes images of mystical inventory items found in an MMORPG. Think Diablo1, Runescape2 or maybe even Star Wars: The Old Republic3 for those fans of space operas.

But no, unfortunately this post isn't about those type of caches. This is about something you'll come across in computing. The LRU (Least Recently Used) cache.
If this article isn't about those then what is it about? Well it's about Rust, WebAssembly, Pokémon and LRU caches. By the end of this article I'd like to relate these these seemingly unrelated topics. Why? Because I think they provide an interesting way to understand LRU caches. So follow along!
What Are LRU Caches?
A better question to answer first is: what is a cache? Simply put a cache is:
the hardware or software component that stores data so that future requests for that data can be served faster
In this case we are dealing with a software cache and the type of the cache in question is a Least Recently Used Cache.
The type defines how we deal with maintaining the size of the cache4. An LRU cache evicts items based on when an item was accessed. As the name implies, items that have not been accessed recently will be evicted when the cache exceeds it's maximum amount of items.

In the example above the capacity of the cache is 4, the maximum number of items. Items are accessed and added. There are two iterations of interest:
- Iteration 5: We replace A with E as A had been the least recently used (0 times)
- Iteration 7: In a similar vain E is replaced with F as E had been the least recently used (1 time)
Makes sense. But how do we go about implementing an LRU cache? Perhaps there are a couple of data structures that can come in handy for this type of problem.
Implementing an LRU Cache
Thinking through what's needed for an LRU cache, two things come to mind:
- Fast access, this implies constant time
- At the same time, a way to keep track of which items have been used and evicting them easily
In the spirit of a great problem there are many ways to solve this one. However, in the same vein TL;DR, we will only explore one of them. That one will involve two fundamental data structures: hashmaps and linked lists, both which lend themselves to deal with the properties above elegantly.
Hashmaps, Linked Lists and Caches
Putting the puzzle pieces together to create an LRU cache works as follows: we create a hashmap with items in the cache as keys and the values pointing to nodes in a doubly linked list.

A hashmap will satisfy but why a doubly linked list? Doubly-ness aside, a linked list is useful here because we can keep track of the head and tail nodes.
Whenever we access an item, we move it to the head, as it has become the most recent. Once the linked list exceeds it's capacity, we can remove the tail as this will be the least recently used item. The new item becomes the head.
Bringing back the doubly-ness, the utility from this property is that it makes removing nodes simpler because we always have a pointer to the previous and next nodes relative to the current node. We need this information when removing nodes.
The code5 below in Python, which is pretty simple, would look something like this:
def delete_node(self, dele):
# Base Case
if self.head is None or dele is None:
return
# If node to be deleted is head node
if self.head == dele:
self.head = dele.next
# Change next only if node to be deleted is NOT
# the last node
if dele.next is not None:
dele.next.prev = dele.prev
# Change prev only if node to be deleted is NOT
# the first node
if dele.prev is not None:
dele.prev.next = dele.nextPutting it all together, we have something that resembles the diagram below, with our first sighting of Pokémon. Here we have a map of Pokémon pointing to linked list nodes that can contain any relevant data that we need.

An Implementation in Rust
Firstly, why Rust? I enjoy systems programming and I have wanted to experiment with WebAssembly (Wasm) and thought this would be a good idea. Boy was I wrong. Before we dive in, let's quickly sidestep and ask ourselves why this was a bad idea.
Linked Lists and Rust
Apparently these two don't mesh well together. You can find discussions on linked lists in Rust6, tutorials on how create them in Rust7 and why they are hard to write in Rust8. For a hobby and educational project I clearly bit off more than I can chew. I didn't want to use a crate9 for the linked list because I wanted to implement something myself to maximise my learnings.
If I wanted to continue to use Rust for this project, I'd have to adapt and find new ways to implement the cache. Moments like these teach you more deeply about what a programming language is well suited for. Rust clearly is not well suited10 for linked lists.
This leaves no choice but to explore different data structures for the implementation in Rust. Enter: double ended queues (deque).
Deques
A deque is a data structure similar to a queue11 but it allows inserting and deleting at both ends of the queue. This allows for the same functionality as having accesss to the head and tail of a doubly linked list.

However, what does the hashmap point to now? The items in the deque are not nodes anymore with left and right pointers. You might be thinking: "we can just store the indexes of each item in the hashmap for constant access!".
You'd be right to think that we are going to store the indexes and slightly right in thinking that we maintain our constant time. Because we have introduced indexes, we are going to have to shift all of these indexes by 1 up until the node we are processing, a worst case operation.
Some of you will probably be raging into the screen thinking that there are better ways to do this. You'd be absolutely correct but at this point I didn't want to get bogged down into making this ultra efficient. It is after all an educational project and meant to be somewhat fun. Plus, we've got Pokémon to attend to!
Implementation in Rust... Again
Before we dive into the code, let's zoom out. What kind of API should our cache have? Fortunately it's pretty simple. Only two operations:
get(value) -> valueput(value)
We want to get values from the cache and put values into the cache. So, without further ado, let's get started!
The Code
We want to define a struct that will hold the model of our cache. It will have a capacity defined by the user, hence the only public field is pub capacity: usize.
pub struct LRU {
pub capacity: usize,
map: HashMap<String, usize>,
q: VecDeque<String>,
}I've chosen to simply map a String to the index as I'm going to go with uuids12 to link any arbitrary item in the cache.
I've defined two helper methods to manage the state of the cache as we get and put into it.
fn update_map_values(&mut self) {
for (idx, key) in self.q.iter().enumerate() {
self.map.insert(key.to_string(), idx);
}
}
fn make_node_head(&mut self, idx: usize, key: &str) {
self.q.remove(idx);
self.q.push_front(key.to_string());
self.update_map_values();
self.map.insert(key.to_string(), 0);
}The first, lazily updates all the hashmap indexes with the new state of the queue. The second will make the value that has just either been put or get into the head node13.
The final methods are the actual user facing get and put.
pub fn get(&mut self, key: &str) -> Option<String> {
if let Some(&idx) = self.map.get(key) {
self.make_node_head(idx, key);
return Some(key.to_string());
} else {
return None;
}
}
pub fn put(&mut self, key: &str) {
if self.q.len() == self.capacity {
let remove_key = self.q.pop_back().unwrap();
self.map.remove(&remove_key);
}
self.q.push_front(key.to_string());
self.update_map_values();
self.map.insert(key.to_string(), 0);
}The get simply gets the value if it's there and makes it the head, otherwise it will return None. Performing a put will, if the capacity is full, remove the tail node14 and then put the item in the cache and make it the head node. That's it!
All together it looks like this:
#[wasm_bindgen]
pub struct LRU {
pub capacity: usize,
map: HashMap<String, usize>,
q: VecDeque<String>,
}
#[wasm_bindgen]
impl LRU {
#[wasm_bindgen(constructor)]
pub fn new(capacity: usize) -> LRU {
utils::set_panic_hook();
LRU {
capacity,
map: HashMap::new(),
q: VecDeque::new(),
}
}
fn update_map_values(&mut self) {
for (idx, key) in self.q.iter().enumerate() {
self.map.insert(key.to_string(), idx);
}
}
fn make_node_head(&mut self, idx: usize, key: &str) {
self.q.remove(idx);
self.q.push_front(key.to_string());
self.update_map_values();
self.map.insert(key.to_string(), 0);
}
#[wasm_bindgen(getter, skip_typescript)]
pub fn queue(&self) -> JsValue {
serde_wasm_bindgen::to_value(&self.q).unwrap()
}
#[wasm_bindgen(getter, skip_typescript)]
pub fn map(&self) -> JsValue {
serde_wasm_bindgen::to_value(&self.map).unwrap()
}
pub fn get(&mut self, key: &str) -> Option<String> {
if let Some(&idx) = self.map.get(key) {
self.make_node_head(idx, key);
return Some(key.to_string());
} else {
return None;
}
}
pub fn put(&mut self, key: &str) {
if self.q.len() == self.capacity {
let remove_key = self.q.pop_back().unwrap();
self.map.remove(&remove_key);
}
self.q.push_front(key.to_string());
self.update_map_values();
self.map.insert(key.to_string(), 0);
}
}You may have noticed that there are some extra methods and macros15 I haven't talked about. Not to worry, these link into the next part of the puzzle: WebAssembly.
WebAssembly
WebAssembly (Wasm) is a type of code that compiles to a binary that can run in your browser16 at native speeds17. It can compile from C, C++, Go and Rust amongst others in the ecosystem. This sounds like a great deal for those looking to improve performance on compute heavy tasks but it seems the jury is still out18.
Nonetheless, I thought trying to run my Rust LRU code in this project could be a cool thing to experiment with. Curiosity is the name of the game here. But how do I go about doing this? Luckily, there is quite a handy crate that can help us out: wasm-pack.
Wasm-Pack
Wasm-pack is a great open-source tool that helps compile Rust code to Wasm and package it so we can use it in our web applications. It's recommended on the mdn web docs19 and makes the process of using wasm in your application a lot easier. This is one of the major benefits of using Rust as the language of choice to compile into Wasm. The ecosystem is more mature and supported than some of the other languages20.
It works by packaging your Rust code as an npm package that we can directly install into our web app by adding it into the package.json. Easy as that! Running wasm-pack build --target bundler will yield something similar to:
$ wasm-pack build --target bundler
[INFO]: 🎯 Checking for the Wasm target...
[INFO]: 🌀 Compiling to Wasm...
Compiling lru-wasm v0.1.0 (/repos/wasm-lru)
Finished `release` profile [optimized] target(s) in 2.17s
[INFO]: ⬇️ Installing wasm-bindgen...
[INFO]: Optimizing wasm binaries with `wasm-opt`...
[INFO]: Optional fields missing from Cargo.toml: 'description', 'repository', and 'license'. These are not necessary, but recommended
[INFO]: ✨ Done in 3.72s
[INFO]: 📦 Your wasm pkg is ready to publish at /repos/wasm-lru/pkg.You may be asking: "why am I setting the target as bundler". Well, in my case I am using Next.js which uses webpack so I could target a bundler and secondly it makes using our package much simpler21.
It's all well and good that wasm-pack bundles our code ready to be imported into a web app but how does it interface with Rust when you are writing Rust code, and for that matter TypeScript?
Using Wasm with TypeScript
Wasm-pack greatly simplifies the process of compiling Rust to Wasm and using it in a Javascript or TypeScript project.
Remember those macros I said I'd talk about, the ones labelled #[wasm_bindgen]? Let's revisit them in this section. They are what expose the functions that will be accessible to both Rust and Javascript22. They can not only be applied to functions but also to structs as per the Rust code above.
So it's as easy as that! Slap on #[wasm_bindgen] and reap the rewards of using those Rust functions in Javascript. Well... not exactly.
You see, the LRU struct has the HashMap<String, usize> and VecDeque<String> fields which aren't supported types in wasm-pack23.
#[wasm_bindgen]
pub struct LRU {
pub capacity: usize,
map: HashMap<String, usize>,
q: VecDeque<String>,
}However we aren't entirely stuck here, instead we can use the serde24 package, which handles sending arbitrary data to Javascript25 for use.
#[wasm_bindgen(getter, skip_typescript)]
pub fn queue(&self) -> JsValue {
serde_wasm_bindgen::to_value(&self.q).unwrap()
}
#[wasm_bindgen(getter, skip_typescript)]
pub fn map(&self) -> JsValue {
serde_wasm_bindgen::to_value(&self.map).unwrap()
}You might be wondering why I've added this new macro #[wasm_bindgen(getter, skip_typescript)] that looks like it's telling the packager to skip TypeScript when the heading of this section suggests an explanation of how to use TypeScript with Wasm.
Creating seamless automated typing from Rust to TypeScript with the current ecosystem is hard26. wasm-bindgen does provide lots of attributes27 that can help export some useful typing for us but it lacks when it comes to the non standard data types I'm using here. If you run wasm-pack you'll get the file:
/* tslint:disable */
/* eslint-disable */
/**
*/
export class LRU {
free(): void;
/**
* @param {number} capacity
*/
constructor(capacity: number);
/**
* @param {string} key
* @returns {string | undefined}
*/
get(key: string): string | undefined;
/**
* @param {string} key
*/
put(key: string): void;
/**
*/
capacity: number;
}Evidently, the map: HashMap<String, usize> and q: VecDeque<String> are missing from the type definitions, as we specified to skip them with skip_typescript. If we chose to include these (i.e removing the skip_typescript) then our types would look like this:
/* tslint:disable */
/* eslint-disable */
/**
*/
export class LRU {
free(): void;
/**
* @param {number} capacity
*/
constructor(capacity: number);
/**
* @param {string} key
* @returns {string | undefined}
*/
get(key: string): string | undefined;
/**
* @param {string} key
*/
put(key: string): void;
/**
*/
capacity: number;
readonly queue: any;
readonly map: any;
}which isn't very useful in TypeScript. How do we get around this? It's not very straightforward. I tried multiple solutions using different crates28, using typescript_type29 but nothing suited what I needed.
Instead I chose to generate what I could with the bindings (as seen in the first lru_wasm.d.ts) and extend the class on the frontend.
export class LRU extends WasmLru {
readonly map: Map<string, number>;
readonly queue: Array<string>;
}Finally, we have packaged the wasm module and have it typed. What's next is to actually use it.
Wasm and MDX
I use MDX to write blog posts. It allows for more interesting posts that can utilise the magic of React components and embed them into your markdown. It's awesome. I decided to try my hand at including a React component that uses the wasm module built above in an interesting way.
As has been the central theme to this project, it wasn't easy to integrate the wasm module into MDX on Next.js. Thankfully I came across an article30 that explains a workaround for using wasm on Next.js, however this wasn't the end of the woes.
Since MDX is rendered on the server, I was getting an error when bundling31 my wasm component with my MDX files. The solution here was to load the module dynamically and to not render it on the server.
import dynamic from "next/dynamic";
const DynamicWasmModule = dynamic(
() =>
import("@components/mdx/WasmModule").then(
(mod) => mod.WasmComponent
),
{
ssr: false,
}
);Now the show can finally begin: running wasm code on the client used in this very mdx file.
Using The Cache
I'm going to posit an interesting application of an LRU cache that includes Pokémon. Yes those things. Remember the Pokédex? It's pretty much a device that acts as an encyclopedia of Pokémon. But it only applies to ones you've caught or seen.
We are going to implement a special spec of a Pokédex.
The Spec
Since obviously the technology in the Pokémon universe is still stuck in the 60s32 our Pokédex can only hold a maximum of 10 Pokémon, using the Signetics 8-bit RAM chip.

As we explore Pokémon, we want to make wise choices on how we store and get rid of Pokémon once we find more. Let's say that Pokémon that we look up a lot are more important than ones we don't. In other words we want to scrap the Pokémon accessed the least.
The LRU Cache seems like a perfect data structure to use behind the scenes of our Pokédex.
Implementation
We will need a way to represent this problem in terms of an LRU cache. I suppose we would need a way to map a Pokmeon to an item in the cache. One way to do this is to assign a uuid and map that to a Pokémon. The map then has keys as uuids that point to the underlying data structure that contains the Pokémon. It would like something like this:
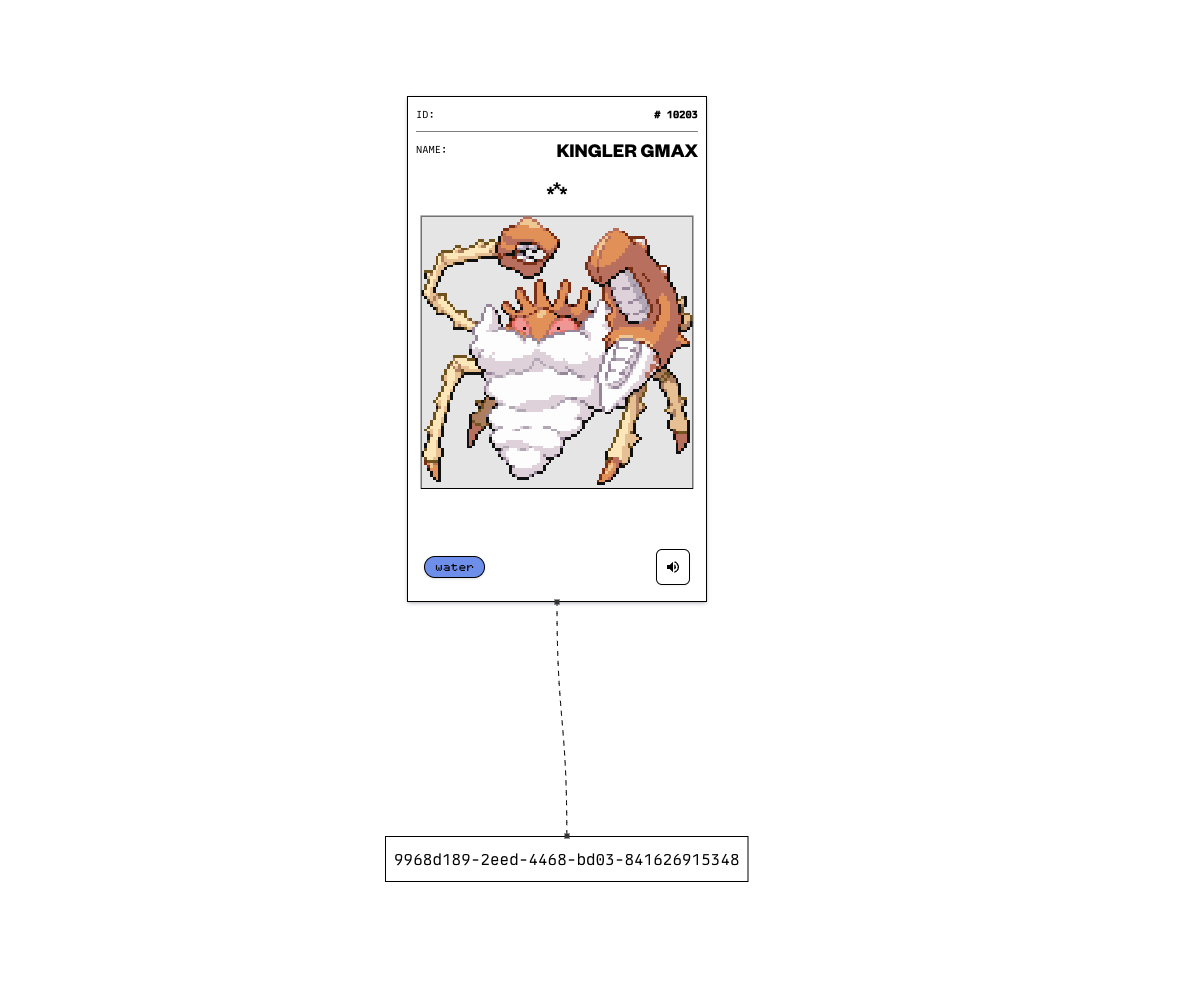
Great! Then our cache can handle the size by setting it's capacity and also the eviction of Pokémon we don't really view that much. Cool, but what does it look like in action?
Pokédex
I decided to build this React component Pokédex using the wonderful react-flow library33 to model what the inside of this Pokédex might look like. This is an MDX component that is running the wasm module we built earlier as the LRU cache along with some other React magic.
Try play around with it and see what happens! You can adjust the cache size, explore Pokémon, and retrieve the Pokémon. All these actions affect the underlying data structures34 so we can see how adding, accessing and removing Pokémon work in practice and in relation to the LRU cache. You can drag, zoom in and out, and move the nodes around.
It will35 obey all the rules of an LRU cache as you perform the actions above. Use it to learn and visualise what happens under the hood of an LRU cache.
As you can see, LRU caches have some real-life applications. Whilst Pokémon are arguably not real, building devices with constraints that match an LRU cache are.
The End
This project took a lot longer than I thought it would. I ran into loads of obstacles with Rust, Linked Lists, WebAssembly, Next.js and all the things we covered in this post. Was it frustrating as hell? Yes. But did I learn a lot from it? Also yes.
This is what software engineering is all about, banging your head against the wall and building something for the sake of it, and sharing it with the world. I hope this post inspires you to go build random stuff and reap the joy of figuring stuff out along the way.
Contact
If you have any comments or thoughts you can reach me at any of the places below.
***
Footnotes
-
This one is more pertinent to the type of cache we are talking about ↩
-
More specifically we say the eviction policy tells us what type the cache is ↩
-
They are quite contentious apparently ↩
-
Rust's internal package manager ↩
-
Simply anyways ↩
-
If you want to know more about queues, just visit wikipedia ↩
-
They aren't really nodes as we are using a deque now, but thought I'd keep the semantics consistent ↩
-
The least recently used node!!! ↩
-
A great critical read about why maybe performance isn't the best feature of wasm ↩
-
I'm loooking at you Go ↩
-
Pretty much you have to manually
initthe module in auseEffectinstead of simply importing and using the package if you don't target a bundler. ↩ -
They are one of the most important things to know about
wasm-pack↩ -
Useful for serialising and deserialising Rust data structures ↩
-
I was banging my head with
tsifyandts-rustand searching online and using Claude and couldn't really find something that worked easy ↩ -
For instance I used
skip_typescript,getterandconstructor, see the docs here ↩ -
This did look promising however going with this approach would mean just re-writing the whole type from scratch, I wanted to use a mix of automated and patched ↩
-
I use Kent Dodds blazingly fast mdx bundler ↩
-
I recommend this library for anything graph and node based. Even Stripe use them for their docs! ↩
-
The uuids represent the hashmap and the pokemon cards represent the deque. ↩
-
If you find any bugs let me know! ↩
A big thanks to Deirdre Murray-Wallace, Joe Eid, Spike Jensen and Martin Rabone for reviewing this post and making it better.